Predicting Friends
I’ve got a running app (the one I discussed in my old blog), with actual real users! This means a trove of extremely interesting data to work with :)
Idea
I’m managing a social network, and I have data from numerous users, their interests and where they’ve traveled. How can we harness this information for cool new features?
Here’s a list of functionalities I’d like to implement:
- Suggest travel destinations
- Recommend new friends based on chat history
- Offer personalized entertainment suggestions based on visited locations
All these are achievable with the power of Machine Learning with Graphs. So, let me provide a brief overview of the theoretical concepts that make all of this feasible.
Graph
First off, what exactly is a graph? Simply put, it’s a collection of nodes and edges representing certain data.
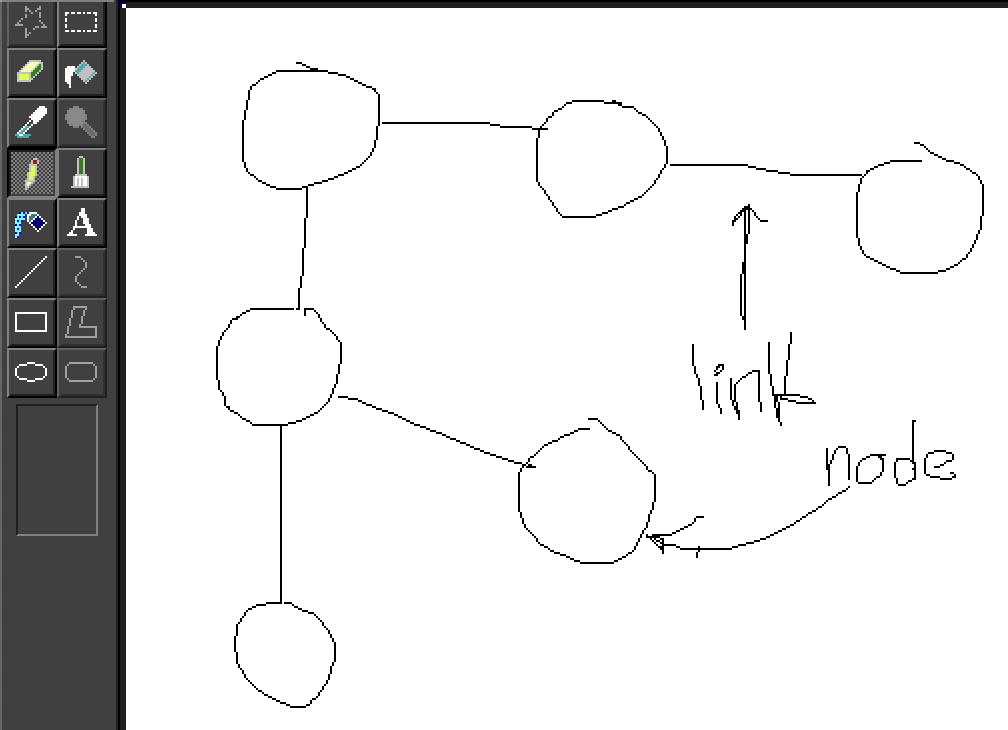
For a social network, nodes could represent people and edges their relationships. In chemistry, nodes might be atoms and links the bonds between them. For cuisine, nodes could be ingredients linked based on their flavor profiles (sweet, sour, salty).
The possibilities are endless. In my case, I’m getting this user info:
- Countries they’ve visited
- Users they communicate with
- Specific places they’ve been to (nightclub vs library) [Note: This feature is not yet in the official release; it’s still in testing]
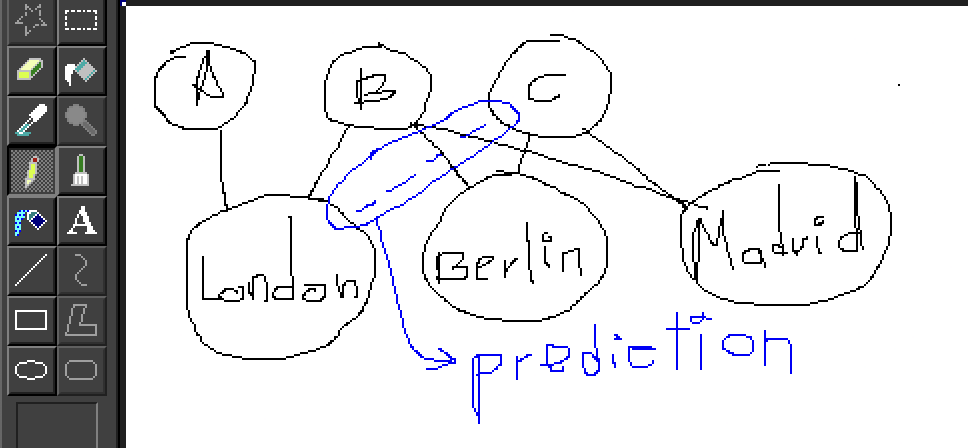
We can leverage this data to predict potential chat partners, new travel destinations, and relevant suggestions.
Embeddings
The first step is to transform the graph into a format that’s digestible for an ML model. This transformation is known as embedding, where relationships in the graph are represented as vectors. Nodes with similar attributes in the graph will have similar vectors in the embedded space.
So, vectors close to each other on the graph are close on the embedding space.
Imagine it as taking a graph:
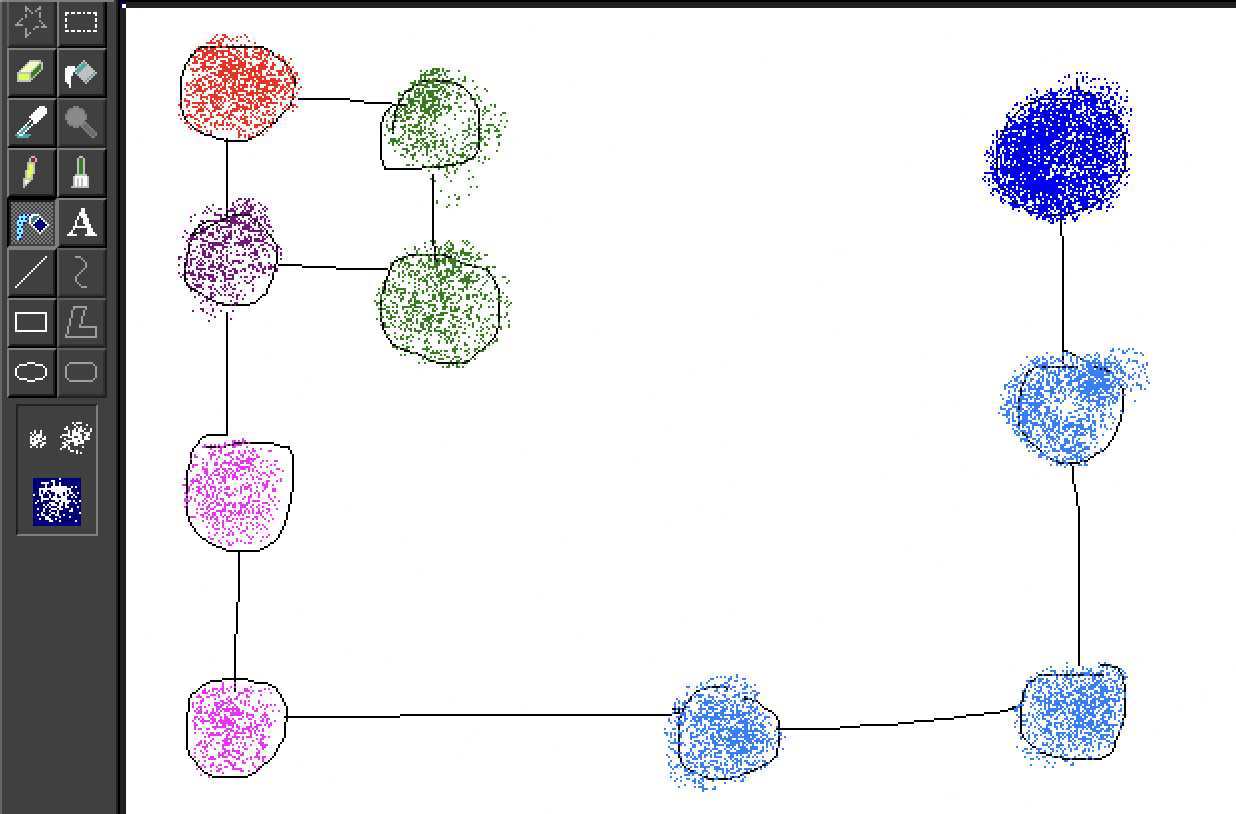
And through embedding, we assess the proximity of points to one another (in this case, in 2D):
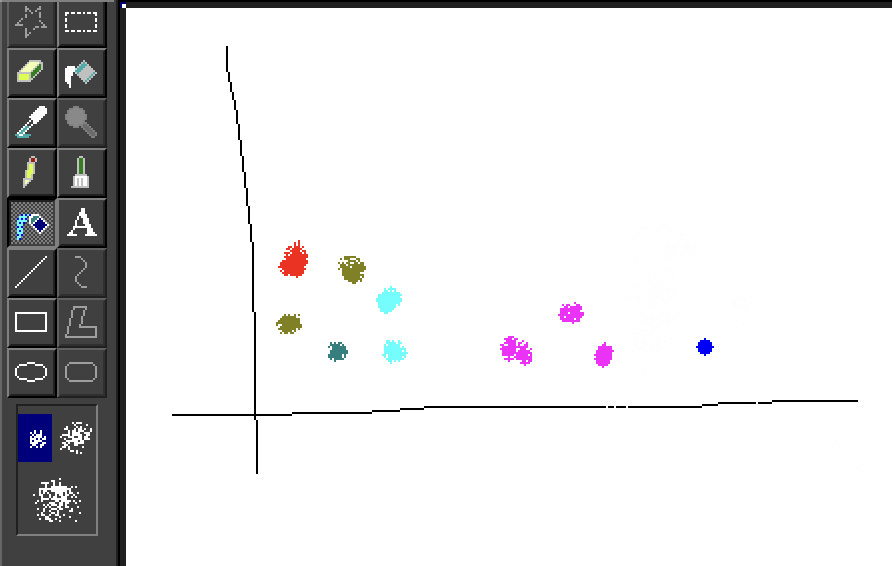
There are numerous methods to embed a graph, depending on the features you want to prioritize. A trivial method might be to zero out the entire vector except at the position corresponding to the node.
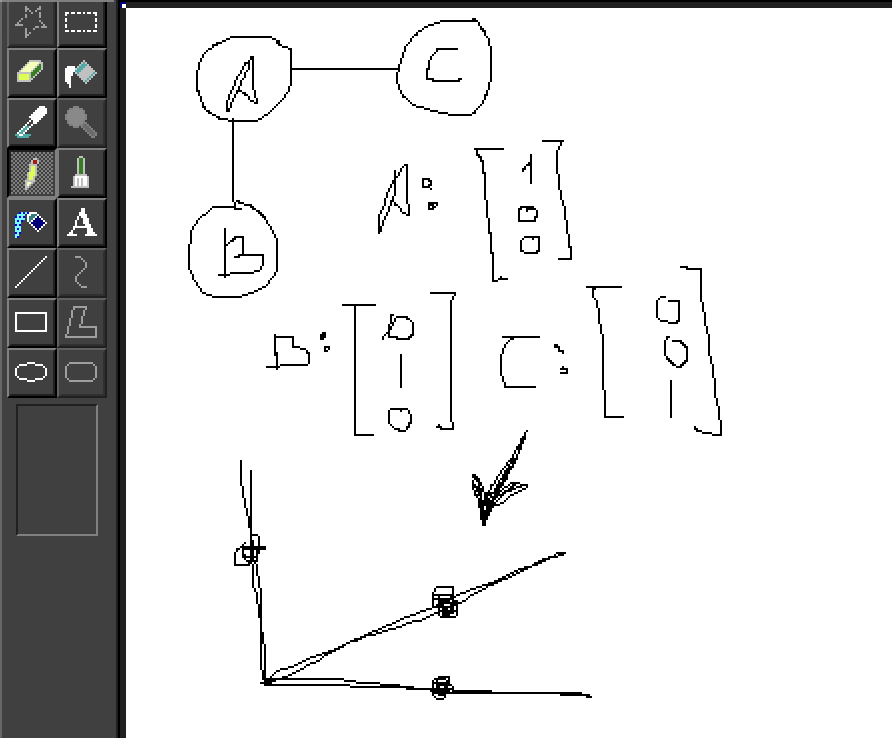
However, more sophisticated options exist. A common method involves using Random Walks.
Similarity
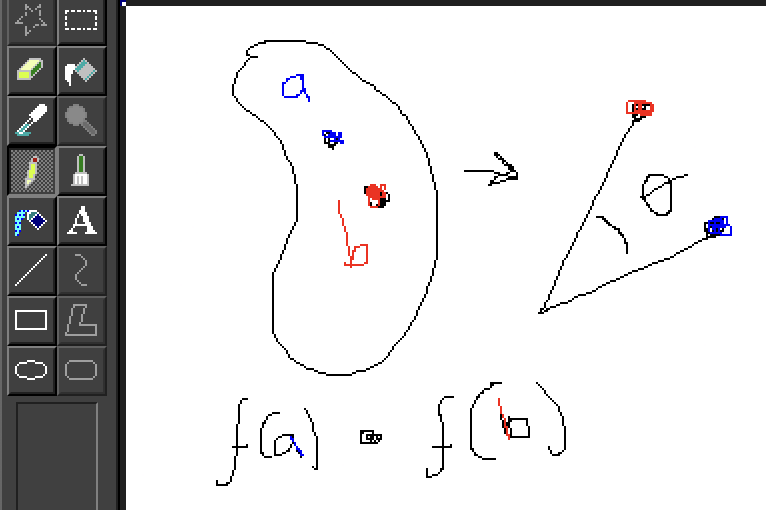
What does “similar” mean exactly? For the embedding space, this is simply the dot product.
If we had a function that takes a node a and outputs the emebedding vector f(a) -> []. Then you could calculate the similarity between two nodes in the embedding space simply as the dot product of f(a) and f(b).
Random Walks
A Random Walk involves starting at a specific node (let’s call it node i) and then randomly traversing to other connected nodes.
For a random walk of length 5:
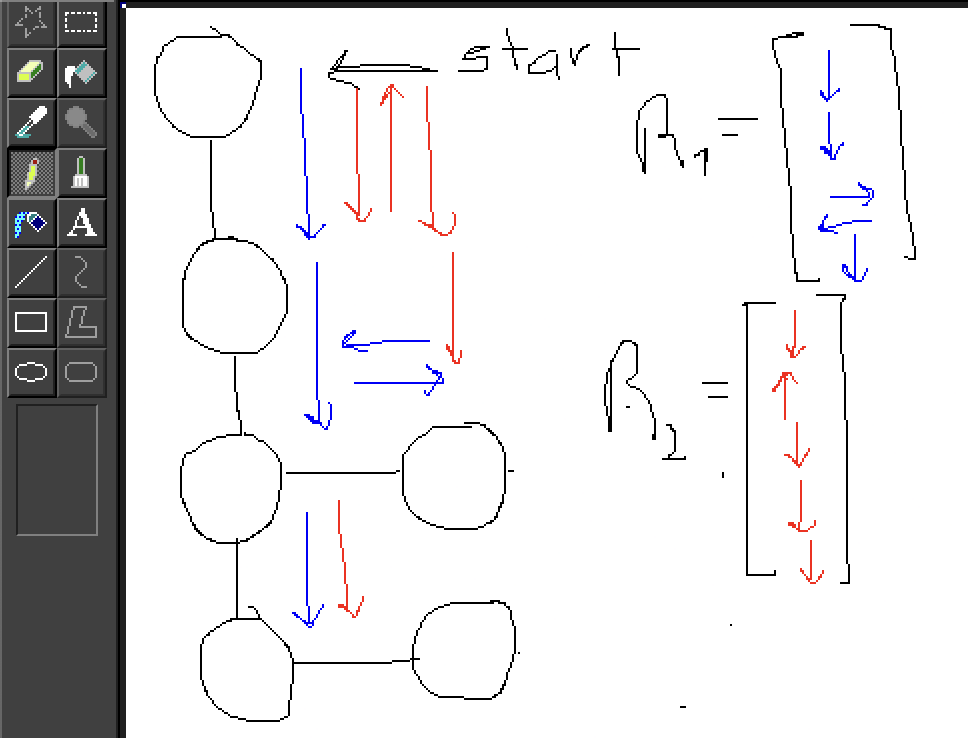
This method is valuable because if there’s a high probability of a random path existing between two nodes, it’s likely they’re either close to each other or share multiple paths.
You can perform just n random k-length walks over a graph for each node, a technique known as Deep Walk. Alternatively, you can introduce biases. For instance, you might adjust the probability of returning to the original node or continuing further away from the starting point.
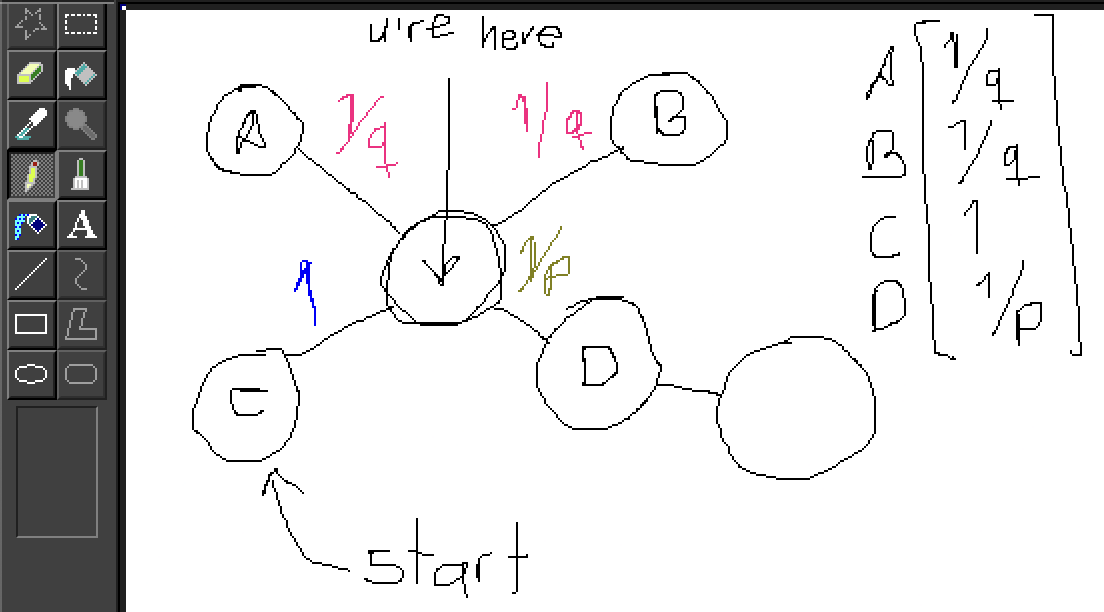
Low p means high probability of staying. Low q means high probability of going further away.
This biased approach is termed node2vec.
Of course, this is a simplified explanation. The underlying math is intricate and fascinating.
Predicting Friends
This information alone is quite useful! We can see how close users’ are (cannot share bc of privacy).
We can now use this encoded information information to train models and make super interesting predictions. I’ll write next part regarding the actual model implementation.
suun!
I’m currently working on optimizing these models for suun users. Expect these features in our next major update!